Encapsulation, Polymorphism, and Abstraction in Ruby
The Foundational Building Blocks of Object-Oriented Programming
Did you know that Ruby was good for the environment? It is, because it follows strict EPA principles… Encapsulation, Polymorphism, and Abstraction. [Ducks a volley of Tomato objects thrown at him].
In a previous post, we discussed the importance of classes in OOP, and developed the mental image of classes as providing more defined jobs and roles to our data. To summarize: classes allow us to build applications that scale well and deal with more complex and customized data structures. They do this by enabling us to store data in specific ways (i.e., attributes) and to interact with this data both internally and from the outside world, also in specific ways (i.e., behaviors, or methods).
In this article, we’ll define and understand all the following terms and concepts: encapsulation, polymorphism, abstraction, method access control, class inheritance, single inheritance, multiple inheritance, duck typing, is-a relationship v.s. has-a relationship, collaborator class and collaborator objects, syntactical sugar, superclass, nil v.s. nothing, dynamically typed v.s. statically typed, interface inheritance, mixin, namespacing, collisions, composition v.s. inheritance, method lookup path, overriding inherited methods, ancestors, and classes v.s. modules.
In the process, we’ll enrich and solidify our understanding of OOP principles, and more fully appreciate the many ways Ruby empowers us to write beautiful, concise, safe, and DRY code. Let’s get to it.
Building Blocks of OOP
There are three pivotal concepts and building blocks of OOP in Ruby. They are:
-
Encapsulation - Protecting access to data and functionality so that these are unavailable to certain parts of the codebase is how we ensure data is only intentionally accessed and correctly manipulated. The data is thus encapsulated, or shielded.
Through the use of class objects, we can create instance variables and instance methods that are encapsulated and thus only accessed by either the object’s class or the object itself, but nothing else. Through the use of method access control, we can even further encapsulate these so that even the object itself does not have access to them. Method access control allows us to qualify instance methods as public, private, or protected, which impacts how accessible these interfaces are to the outside world.
Encapsulation also enables abstraction, the third principle of OOP. We could think of abstraction as a subset of encapsulation, but it’s such an important concept that many think it deserves to be a standalone principle–and I agree. Encapsulation is also itself meaty and important enough–even without its role as the father of abstraction–to remain a standalone principle.
(Also: I’ve been wanting to describe something as “the father of abstraction” for a while now, and this was the perfect setup. I wish it was referring to me, but I guess encapsulation is the better man. Alternatively, I could have a kid and name her/him Abstraction. Then, at last, I could claim this glorious title. What? No, she wouldn’t mind.) -
Polymorphism - Literally means “having multiple forms.” When objects of different classes have access to the same interface (i.e. method), they are polymorphic. The idea is that the common method reveals and expresses itself in the many different (class) forms or objects it inhabits.
The religious studies student in me cannot help but to point out how similar this concept is to polytheism, incarnation, and manifestations of God or the Holy Spirit, where the same divinity takes on many forms, physical or otherwise.
Polymorphism can be accomplished through three main ways in Ruby: class inheritance (i.e. from a superclass, establishing an “is-a” relationship), interface inheritance (i.e. from a module mixin, establishing a “has-a” relationship), and duck typing. We’ll get to each of these later.
Sidenote: some place inheritance as a standalone, fourth principle of OOP, especially in the context of Java. Doing so in Ruby makes less sense, however, because the only practical application of polymorphism as applied to Ruby is the idea of inheritance.
If we extracted and placed inheritance as a standalone principle, polymorphism would just be an empty shell. Plus, we’d also have to do away with that brilliant EPA joke and replace it with some lame E-P-A-I joke that doesn’t even make sense, like:
– “What did the Canadian Rubyist respond when he was asked to incorporate OOP principles?"
– “API, Eh?"
See? You’re welcome. -
Abstraction - The ability to simplify complex state and sets of behaviors into one unifying entity makes a programmer’s life easier, because all of that complexity is abstracted away and replaced by that umbrella entity (e.g. a class object). This allows us to more easily conceptualize what an object does, how it behaves, and how the outside world should interact with it.
For example, for a card game application, we may create aDeckclass that contains, as an attribute, an array of cards, where cards themselves could be objects of aCardclass. TheCardclass may have several attributes, includingsuitandface. OurDeckclass may also contain several behaviors, includingdeal,shuffle, andcount(to return how many cards are left in the stack). This makes our life easier, because we can more abstractly just think of aDeckobject, and not have to worry about all of its methods and attributes, which will remain encapsulated in and “travel with” thatDeckobject everywhere it goes.
In this example, both theCardclass and theArrayclass are said to be collaborator classes of theDeckclass, since theDeckclass incorporates them as attributes. We can think of collaborator objects as lower levels of abstraction of the owner object whose class incorporates them. We can therefore imagine scenarios of multiple nested collaborator objects, each producing various levels of abstraction.
Another example of abstraction is syntactical sugar, which is when a language offers an easier or simpler way of doing something. For example, using[]to return a specific element at a particular index in an array (or to return a value with that specific key in a hash) is a form of syntactical sugar.
Under the hood, callingsome_array[4]is the same thing as callingsome_array.[](4). The[]is actually just an instance method that takes an argument, which is the key or index. This[](arg1)method has been abstracted away and simplified by the smoother[arg1]method. (Note: both versions can also take an optional second argument and thereby mimic theArray#slicemethod, allowing us to capture a range of elements).
Similarly, doingsome_array[3] = 5is the syntactical sugar equivalent ofsome_array.[]=(3,5). Under the hood, we are just calling an instance method named[]=onsome_array, and passing it two arguments: the index number, and the value we want to set the element at that index number to. The[a]=bform is a more abstracted version of the.[]=(a,b)form.
To conclude, here’s a random abstraction joke so that it doesn’t feel jealous of the fact that the other two OOP principles got to have jokes:
What did the agitated but confused programmer-turned-public defender yell when the prosecutor was making an overly simplistic generalization about the defendant?
– “Objection, your honor!"
– “On what grounds?"
– “Abstraction!"
I mean I could go all day.
All the three principles of OOP identified above allow our code to be 1) DRY (don’t repeat yourself), 2) more maintainable, and also 3) easier to understand and conceptualize.
Now that we’ve defined the three main principles of OOP, let’s see how classes and modules help us achieve them, and how both of these work together to create the concepts of method lookup path and ancestors.
Here’s a diagram that shows the relationships between modules and classes, and some of the most common instances of these that come prepackaged in Ruby.
Classes are in the light grey rectangles, and modules are in the green clouds.
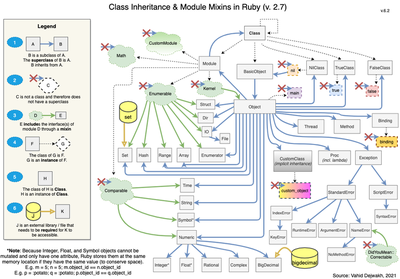
Class Inheritance
Ruby comes with multiple built-in classes, including String, Integer, Hash, and Array. These four classes are probably the most frequently used collaborator classes for any custom classes we might want to create.
Each class is itself an object (or instance of) the Class class, which we can think of as the primordial class, sort of like the Biblical Adam and Eve of all classes.
What is class inheritance? Every class inherits methods and attributes from another class, which we refer to as the class’s superclass. Calling the class method superclass on any class will return that class’s superclass. For example: puts Integer.superclass will output Numeric.
Every class has one (and only one) superclass. This is called single inheritance because a class can only have a single parent. When we create a custom class without explicitly defining a superclass to inherit from, our custom class implicitly inherits from the Object class.
In the diagram above, we see that the superclass of Numeric is Object, and the superclass of Object is BasicObject. What’s the superclass of BasicObject? It’s nil.
Sidenote 1: the difference between nil and nothing
Nil is not the same thing as nothing, however. Although nil is not a class, it is an object, an object of the class NilClass, whose superclass is Object.
Why is this distinction important? After all, if we have an array, some_array, containing 5 elements, and we call some_array[10], we’d get nil back. Doesn’t that mean that nil is the same thing as nothing?
It appears that way, but it’s not. The reason we get nil back is because the [] instance method, as defined in the Array class definition, is explicitly defined to return the nil object if there’s no key that matches the argument (i.e. the index) passed in to the [] method.
If we instead use the fetch instance method, however, which contains no such safety measure, we’d get an error back if we try to search for a key that doesn’t exist. So when there is nothing, we get an error. If there is something, even if it’s nil, we get that something back (i.e. we’d get nil back). This means that nil is not the same thing as nothing.
Sidenote 2: Ruby has no Bool(ean)
Note, too, that Ruby doesn’t have a “Boolean” class, which is unlike most other OOP languages. Ruby does have separate TrueClass and FalseClass classes, but there’s no overarching “Boolean” class from which both might inherit–instead, those two classes each directly inherit from Object.
The reason for this has to do with the fact that Ruby is dynamically typed (as opposed to statically typed like C++ and Java). This means that in Ruby, we don’t need to explicitly define what the class of a variable is. We instead dynamically (and implicitly) assign it a class, and can easily reassign it to another class (for better or for worse). A variable can therefore easily be assigned to true, an object of the TrueClass class, and then reassigned to false, an object of the FalseClass class.
Finally, as this more in-depth answer to this question argues, there just aren’t enough shared behaviors between the two classes to warrant creating a common superclass. Yukihiro Matsumoto, the creator of Ruby (and affectionately known as Matz by Rubyists), has explained why he rejected calls to create a Boolean superclass.
Duck typing
The previous discussion is a perfect segue to duck typing. In Ruby, we are less concerned with what the class of an object is, and more with its capabilities, i.e. what instance methods we can call on it. If objects A and B are of different classes but they can both respond to a quack instance method, for example, then we can treat both as ducks (hence the name). If it quacks like a duck,…
To accomplish duck typing (i.e. not class inheritance), we can just merely explicitly define the same method in each class definition. Then, for example, we can call that method on any object of any of those classes, and we will get an acceptable, proper return. Duck typing is another, more explicit way to achieve polymorphism.
Is class inheritance the only way to inherit functionality? No–in Ruby, modules also allow this through interface inheritance. Let’s dig into them next.
Modules and Interface Inheritance
All modules are objects of the Module class, which is itself an object of the Class class. Modules play two main roles in Ruby’s implementation of OOP principles:
-
Interface inheritance - We can include the functionality of any module into any class by using the keyword
include, followed by the module’s name. Also known as a mixin (an abbreviation of “mixed in”), this allows all objects of that class to have access to all the instance methods defined in the module.
As the diagram shows, several native Ruby classes mix in either theComparableor theEnumerablemodule. A common naming practice when creating a module that is used as a mixin is to name it with something that ends with “-able”–this makes it more easily identifiable and distinguishable from the other main type of module, used instead for namespacing.
Because there’s no limit to how many modules you can include in a class, modules is how Ruby enables multiple inheritance. If a class needs to inherit two (or more) distinctly different sets of behaviors, you can’t use class inheritance to do this, but you can use a mixin instead. -
Namespacing - Modules can also double up as containers for any number of constants, classes, and/or isolated methods that don’t really belong to any specific class. A great example of modules as a namespace is the
Mathmodule, which contains mathematical constants likeMath::PIand methods likeMath.cos(also accessible withMath::cos, though the former is the preferred way for calling module methods). This can be particularly useful when creating libraries/gems, or even when different team members are working on different features of a common application.
Namespacing is a practical way to not only organize related behaviors together, but to also prevent collisions. There’s a likely possibility that more than one member of a large team (or that more than one gem or library) might name a custom class the same way, which would cause one class definition to collide with and override the other when they merge their code into the same branch, or when they combine those gems or libraries together.
Instead, they can place their class definition inside a module which could be named after their particular feature or gem, for example. That way, they can more explicitly access the class inside the module that they created, which would be distinct and encapsulated away from the same class inside another module.
For example, let’s say Amanda and George both had to create aStudentclass for the feature they were building. However, Amanda’s implementation focused on the financial side of the application and had to track how much tuition the student had paid so far, and how much they still owed, etc. George, on the other hand, was working on an academics-focused feature and using theStudentclass to track all the classes each student had taken, their grade for each class, cumulative GPA, etc.
Amanda can use namespacing and create a module calledFinances, then define herStudentclass inside there. Anytime she wanted to instantiate a new student for her purposes, she could callFinances::Student.newand pass in any necessary arguments.
Similarly, George could create anAcademicsmodule, and define hisStudentclass there. He would instantiate a new student by callingAcademics::Student.new, along with any necessary arguments.
Sidenote 3: Composition v.s. Inheritance
In some OOP languages, the terms “inheritance” and “inherit” are exclusively used in the context of (and more narrowly used to refer to) when a class receives interfaces from a superclass (i.e., what we’ve had to qualify as class inheritance because of our broader/looser use of the term “inheritance”). While we described a mixin as an example of “interface inheritance,” they would instead call it an example of a composition.
This is worth noting here only because Composition over Inheritance is a specific OOP design pattern that argues that favoring “has-a” relationships (i.e. through compositions, or mixins) ensures our code is more flexible and reusable than using “is-a” relationships (i.e. through class inheritance). This is why the Go language does not even allow class inheritance, and only uses compositions.
For our purposes, we can think of “composition” as just another term for a mixin, and appreciate that to some people, we may sound redundant when we say “class inheritance.”
Method Lookup Path
Now that we’ve covered both class inheritance and module mixins, we can conceptualize the method lookup path (sometimes also called the method lookup chain). Whenever an instance method is called on an object, Ruby looks for that method definition in that object’s class definition. If it doesn’t find it there, it searches for it in any and all modules included in the class, from bottom up. Finally, if it doesn’t find the method in the modules included in the class, it goes up the class inheritance chain and looks for it in the class’s superclass.
It keeps going vertically up the class inheritance tree, then horizontally through all mixins of that class, then up again, etc, until it hits the BasicObject class, which is the last stop.
Let’s look at an example. If we have an array, some_array = [3,6,9], and we then call some_array.max, Ruby will search for the definition of the max instance method first in the Array class definition, since some_array is of the Array class. Notice from the diagram that Array includes the Enumerable module, which means that’s where Ruby will search next. If it didn’t find it there, it would then go up to the superclass of Array, which is Object, then to Kernel, which is a module mixed in to Object, and finally up to BasicObject. Again, the superclass of BasicObject is nil, so that’s always going to be the tail-end of our lookup path.
The method lookup path helps to explain the concept of overriding inherited methods. Because Ruby looks for the method in the class itself first, we can “override” a method that a class inherited from a superclass or module by explicitly defining it in the class. Ruby would therefore use that lower-level version of that method and never get to the version of the method that’s defined further up the method lookup path.
In order to figure out all the modules a class includes, the class method included_modules is useful. This class method travels up the method lookup path, and returns all the modules it encounters along the way, as an array.
For example, Hash.included_modules would return an array of two elements, Enumerable and Kernel, which are the two modules that Hash objects inherit from, since Hash directly includes Enumerable, and Object includes Kernel.
Even more useful is the ancestors class method, which returns the entire method lookup path itself, also as an array. For example, calling Integer.ancestors returns: [Integer, Numeric, Comparable, Object, Kernel, BasicObject]. Note that ancestors is a class method, so we couldn’t call it directly on an object. We’d have to first call the class instance method to return the object’s class, and then call ancestors on that.
For example:
some_num = 4
p some_num.class.ancestors
Conclusion & putting it all together
Wow. You’ve made it this far–kuddos to you!
As a reward, here’s a useful table to recap the three main OOP principles, and how classes and modules help us implement each one.
| OOP Principle | Classes | Modules |
|---|---|---|
| Encapsulation | * Classes shield class variables and class methods * Each object of a class shields its own unique instance variables (i.e. state) * Method access control shields object-specific data and behavior even further by allowing us to qualify certain instance methods as private or protected |
Namespacing allows modules to shield variables, constants, methods, and even classes so that they don’t collide with other similarly named objects |
| Polymorphism | Class inheritance and duck typing | Interface inheritance |
| Abstraction | Instantiating objects from a class allows each object to abstract away its internal complexity through an “is-a” relationship | Including a module through a mixin abstracts away some behavior complexity through a “has-a” relationship |
When should you use classes, and when should you use modules?
Here’s a few guidelines to keep in mind when deciding:
- If you need to create objects from the same mold, you have to use a class. Modules cannot instantiate objects.
- If data type X is a more specific type of class Y, meaning that X has an “is-a” relationship with Y, then it makes sense to use a class to define X, and have it inherit from its superclass, Y
- If Y and Z are unrelated classes that both need to inherit the same functionality of X, meaning Y and Z each have a “has-a” relationship with X, then it makes sense to use a module to define X, and have both Y and Z include X through a mixin.
- If you want a way to compartmentalize a set of behaviors or classes, use a module.
Special thanks to the Launch School curriculum, TAs, and students who all helped me solidify these concepts.
Questions? Confused? Leave your thoughts below.
Vahid Dejwakh
Software Engineer at Microsoft;
Lover of good music and poetry
Vahid writes about interesting ideas at the intersection of software, system design, data, philosophy, psychology, policy, and business. He enjoys coffee and has a palate for spicy and diverse foods.