Parallelism v.s. Concurrency
A quick note on the difference between parallelism and concurrency
Another pair of terms that are easy to confuse are parallelism and concurrency.
Parallelism has to do with many workers working simultaneously. Concurrency, on the other hand, is about being able to make incremental progress on more than one task.
While that may sound like the same thing–and indeed it’s a subtle difference–the practical implications are significant enough to warrant taking a closer look, and parsing out the difference.
Let’s see what this means in practice.
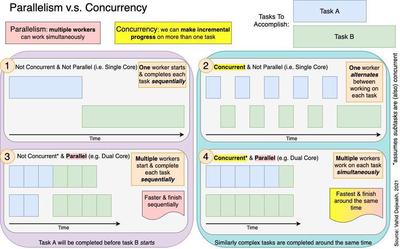
The diagram above shows how two tasks, A and B, are processed under four different scenarios: 1) with neither parallelism nor concurrency, 2) with concurrency but not parallelism, 3) with parallelism but not concurrency, and 4) with both concurrency and parallelism.
1. Not Concurrent & Not Parallel
The simplest to understand is the scenario where there is neither concurrency nor parallelism. Here, each task is completed sequentially by one worker.
Task A must be completed first before we can even start to work on Task B.
2. Concurrent But Not Parallel
When we introduce concurrency to the picture, we now see that the one worker can take a break from Task A, work some on Task B, and alternate back and forth until both tasks are complete. We still only have one worker, so the total time to complete both tasks ends up being roughly the same as scenario 1.
Now, however, as a result of being able to incrementally work on both tasks, we can finish both tasks roughly around the same time.
3. Parallel But Not Concurrent
If we introduce parallelism instead of concurrency, we now are able to have multiple workers working. However, since we don’t have concurrency, it still means that all workers will work on Task A first, finish it, and only then be able to start working on Task B.
As a result of having more workers thanks to parallelism, Scenario 3 is faster than the previous two scenarios.
However, an important note and caveat here is necessary. Although this scenario is saying tasks A and B are not concurrent relative to each other (e.g. because task B is triggered by the completion of task A), the diagram still assumes that the subtasks of task A can be run concurrently, and the subtasks of task B can also be run concurrently.
The diagram of Scenario 3 would look more like Scenario 1 if this assumption were not true.
The important takeaway here is twofold: 1) there can be many levels of concurrency, and 2) parallelism without the proper concurrency is ineffective and results in idle workers.
4. Concurrent & Parallel
The best case scenario is where we have both parallelism and concurrency, and concurrency at many levels. Not only can we take advantage of many workers being able to work simultaneously, but we can also work on different tasks concurrently.
This is the best of both worlds, and allows us to finish all tasks the fastest way out of all four scenarios (as a whole). Because of concurrency, tasks that are similarly complex also finish around the same time.
Rob Pyke on “Concurrency is not Parallelism”
With that as a background, the talk below by Rob Pyke, one of the creators of the Go language, is worthwhile.
Pyke refers to concurrency as a structure that allows us to deal with many things at once, while parallelism is about execution, or doing many things at once.
The structure created by concurrency allows us to take advantage of executing things in parallel.
The diagrams above help clarify why having concurrency without parallelism does not necessarily help to improve speed, especially if we’re dealing with tasks that take a long time. But Pyke drives the point home that having concurrency without parallelism might still be useful from a structural perspective of being able to isolate tasks and work on them independently.
On the other hand, there are situations where, because a task cannot be divided into independent subtasks that can each be completed in parallel, having parallelism without concurrency is mostly useless and results in “workers” not being used. A task whose own structure requires sequential completion, for example, cannot take advantage of parallelism even if the hardware allows it.
For example, in our diagram above, Scenario 3 would look more like Scenario 1 if we were not able to run the subtasks of A and B concurrently. That would mean that we would not be able to take advantage of parallelism, and we’d have idle workers.
For that reason, Pyke suggests that concurrency might actually be “better” than parallelism, but I think the assumed and required subtext there is that most computers now already have multicore processors, so parallelism is typically a given. Because concurrency enables parallelism to shine, and because concurrency without parallelism still has value (but not the other way around), Pyke’s point makes sense.
But of course both are important. Indeed, the ideal setup is one where tasks are structured to be able to run concurrently, and the hardware also enables parallelism.
Vahid Dejwakh
Software Engineer at Microsoft;
Lover of good music and poetry
Vahid writes about interesting ideas at the intersection of software, system design, data, philosophy, psychology, policy, and business. He enjoys coffee and has a palate for spicy and diverse foods.