System Design Interview Cheat Sheet
Helpful overview to nail the system design interview
The system design interview is one of the funnest types of interviews you could get, if you know how to tackle it. The right approach consists of three parts:
1) a playful & collaborative attitude,
2) narrowing down the scope through targeted questions, and
3) understanding the main components of any infrastructure, and being able to use them like lego pieces at your disposal. This post will help mostly with this third part.
Overview
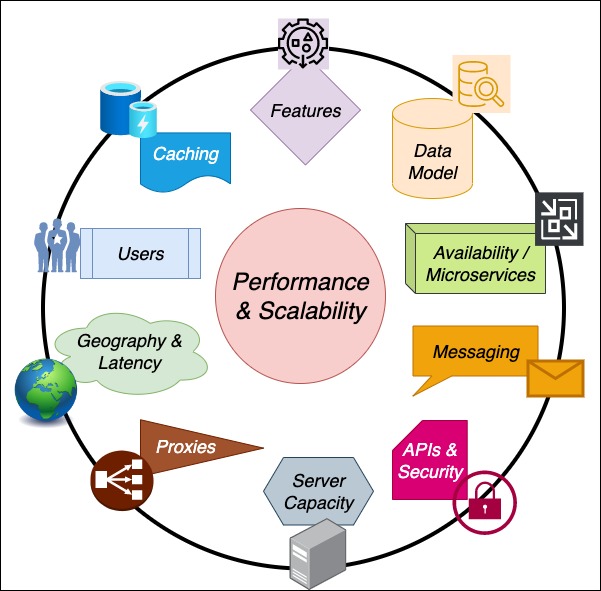
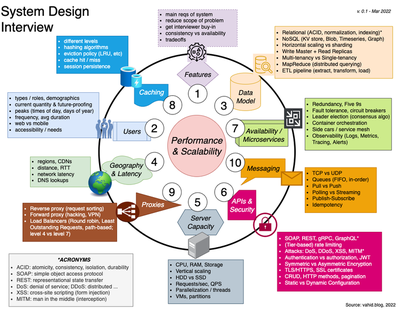
The above diagram captures the 10 main elements that you would need to at least consider during a system design interview. What you actually spend time discussing depends on the prompt you get.
We’ll start with the one-page cheat sheet below, which you can view in better resolution with the PDF version. We’ll then go through each of the 10 elements, in order.
NOTE!
- The categorization of the material into these 10 different topics is highly subjective, and there’s a lot of overlap between topics. This is just how it made sense to me.
- The material listed below and in the diagram is not by any means exhaustive. The goal here is just to get your juices flowing.
1. Features
It’s always good to start with recapping the main features of the system you are trying to build. The prompt you get is typically vague on purpose–so reviewing the features is a good way to sink your teeth into the problem, and make sure you’re on the right track.
For example, the prompt could be “How would you design Twitter?” Start by listing the main features of Twitter, to make sure you and the interviewer are on the same page about what you’re trying to build.
Here, gradually hone in on all the main aspects that the system needs to be able to handle and provide to users. What are the tradeoffs you should make? What’s more important for this system–availability, or consistency? For a bank or e-commerce site, consistency may be more important than availability. What matters is that the user is never charged twice for the same transaction. For a social networking site, availability is typically the better tradeoff–it is not as big a deal if a user’s post appears twice, for example.
2. Users
- Are there different types? (admin, user, etc).
- When do most users use the system, and how many people do we need to serve? How fast is our userbase growing?
- Are there higher loads during a particular time of day? Particular time of the year?
- Do our users log on from different regions?
- Are they accessing the system from a web interface, mobile app, or both?
3. Data Model
For most situations, a relational model works well–it allows for flexibility of reporting and generally can accommodate any future data needs you may need to add later.
Items to consider here:
- What would your most frequent queries be?
- How often are your users adding or updating data?
- How would you design the various tables (assuming relational DB)?
- What fields would you index, knowing indexing generally increases read speeds but decreases write speeds.
- Would it make sense to use one DB as the master to handle all your writes, combined with any number of replicas to handle your reads?
4. Geography & Latency
- Do you need servers in different regions to handle your diffuse users?
- What’s an acceptable round-trip time (RTT) for your users?
- Given the same domain, do you need to point users to a different IP address based on their own IP address?
- Do you need a Content Delivery Network (CDN) to serve different regions?
5. Server Capacity
- What are the CPU, RAM, and storage needs? There’s a physical limit to vertical scaling.
- In terms of storage, SSD is significantly faster than HDD, but much more expensive too.
- How many requests/second does(do) your server(s) need to handle?
6. APIs & Security
-
When is representational state transfer (REST) good enough?
-
Are you having to handle lots of internal microservices, where speed is an issue? Would gRPC be better?
-
If you need to reduce the data pulled by mobile devices, or otherwise want more targeted calls to the database, would GraphQL make more sense?
-
What are the possible security concerns you may have, and how could you mitigate those?
-
How can you use pagination to reduce the results returned from your queries?
-
If you’re supporting an external API, would a tier-based rate limiting system make sense, so that users don’t abuse your API?
7. Availability / Microservices
- If your system needs to have high availability (think five 9s: 99.999% availability per year), how could you ensure this?
- What types of redundancies could you set up so that you’ve always got an available server in case one crashes?
- If you’ve got microservices depending on each other, how can your system be fault tolerant so as to limit cascading failures? Is a tool like Kubernetes a good solution or overkill for your use case?
- How do you allow observability into your system?
8. Caching
- What could you cache directly on the user’s device?
- What would you cache just between a microservice and your database?
- What tradeoffs does adding a caching layer have? How might you mitigate it?
- What type of eviction policy would you use, so that your cache only retains the most relevant data?
- If your users are connecting to your servers through a load balancer, would it make sense to persist their sessions through a cache, which all servers read from?
9. Proxies
- what type of algorithm is better for your load balancer? Is this a OSI layer 4 load balancer or a layer 7 load balancer?
- do you need any other type of reverse proxy? If security is an issue, it might make sense.
10. Messaging
Finally, it might be worthwhile to consider any messaging paradigms and tools you might use, whether for your internal, server-to-server communication, or between end users and your servers.
- Is consistency and reliability important to your system? If so, most of your OSI layer 7 communication will probably be done over TCP then. If you’re doing anything like VOIP or video conferencing, you may instead opt for UDP. If you need a refresher on the two, read this.
- Do you need queues to make sure a communication is never lost, arrives in order, or both?
- Do you need to use some kind of messaging bus like Kafka or RabbitMQ?
- Is a push-based or pull-based mechanism better for your use case?
- Is idempotency important? If so, how could you ensure that the same message is never received more than once?
–
These were just a few things to think about as you tackle a system design interview question.
I hope it’s been helpful. If you need a more in-depth overview along with great examples, I recommend checking out Algo Expert.
As always, feel free to mention a topic that I should cover. Would it fall under one of the ten components (and if so, which one), or would I need to rethink my classifications?
Vahid Dejwakh
Software Engineer at Microsoft;
Lover of good music and poetry
Vahid writes about interesting ideas at the intersection of software, system design, data, philosophy, psychology, policy, and business. He enjoys coffee and has a palate for spicy and diverse foods.