Learn the basics of C in 10 minutes
Time traveling to the world before OOP
If you began your programming journey learning either Java, C#, C++, Python, Ruby, Go, or even JavaScript, this post is here to give you a taste of C, and perhaps interest you in exploring C further.
The C language (the ancestor of all of these languages) is not an OOP language, and instead follows the procedural (aka functional) programming paradigm. What does that mean, and how does learning C help us understand OOP languages better? What benefit do OOP languages provide, and at what cost?
Overview
The main point of this post rests on the premise that sometimes, the best way to truly understand something is to compare it against something it is not. In other words, contrasting OOP languages against C is probably the best way to truly understand what OOP is and means.
There are no “objects” in C. There are no classes, no methods, no instantiating objects of classes, and no garbage collector.
Instead, I would argue that there are only three main structural components to understanding C:
That’s it. Understand these three pieces, and you’re well on your way.
As we’ll see, however, this simplicity both engenders and belies a lot more complexity.
C is to programming languages what chess is to board games. The basic rules are simple to learn. But to truly master and “play” at an advanced level would require many years of diligent and consistent practice.
The closest thing we get to a class and/or an object in C is by defining our own custom struct type, where a struct is a data structure type that can encapsulate any combination of other different types–including, of course, other structs.
But we’re getting ahead of ourselves–let’s back up and learn what types are first. We’ll then learn functions, and end with “the heap,” which is the only way to store variables outside the context of a specific function stack.
Understanding those three main components will not only give us a basic introduction to the simplicity and elegance of the C language, but it will also help us better appreciate what is happening under the hood of an object oriented programming (OOP) language.
1. Types
Just like any other strictly typed language, variables in C must be declared as being of a specific type before they can be used. This helps to ensure that functions receive and return the variable types we expect, which results in cleaner and more maintainable code.
From the machine’s perspective, however, the type of a variable even more importantly determines how much memory the system needs to allocate for that variable–which depends on your system’s architecture and compiler. To store an int (integer), most systems allocate 4 bytes, where 1 byte = 8 bits, and each bit can be either a 1 or 0. With 1 byte, we can store 2^8 combinations, or 256 different combinations. With 4 bytes, we can actually store 256^4, which is 2^32, or over 4.2 billion numbers.
However, because one bit has to be reserved to determine the sign (pos or neg) of the int number (ints can be negative), this effectively halves the magnitude of the possible int numbers to be in the range from about -2.1 bil to 2.1 bil.
If you need numbers of a higher magnitude, you can use a long type instead, which uses 8 bytes, and can store 256^8 combinations, or 1.8 * 10^19 numbers, or 18 million trillion numbers. If you know your int can never be negative, you can also use an unsigned int type which maintains the full 4.2 bil capacity, or similarly an unsigned long for the full, positive-only long capacity.
A char (character) type, on the other hand, only requires 1 byte in ASCII. A string is just an array of chars.
To properly understand how arrays work in C, we need to first understand what a pointer is. A pointer is a variable whose value is a memory address–usually the memory address of another variable. It’s called a pointer because in holding the memory address of another variable, it actually points to the value of another variable.
To declare a variable to be a pointer, we declare it by prefixing a * in front of the variable name.
For example, we’d declare an int variable type with: int num;
We’d declare a pointer to an int with any one of these three different but each technically valid options:
int *numPointer; // (preferred)
int* numPointer; // conceptually makes more sense as a specific var type
int * numPointer;// rarely used
If we want to refer to the memory address of a variable, we preface that variable with a &. To save the memory address of our num variable above into our numPointer (after we’ve already declared both), we can do:numPointer = #
To declare and assign our pointer at the same time, we can do:
int *numPointer = #
When you’ve assigned a memory address to a pointer, you can then access (and modify) the value the pointer points to by prefixing the pointer variable with a *.
For example:
int num = 4; // num = 4
int *myP = # // myP = [memory address of num]
printf("memory address of num: %p\n", myP); // [memory address of num]
int numCopy = *myP; // numCopy = 4
*myP = 7; // num is now 7
// (myP still holds memory address of num; and numCopy is still 4)
As you can tell by the last non-commented line above, the ability to use pointers is a very powerful feature, because it gives us full control over whether we pass by value v.s. pseudo by reference. We saw in the example above that we can even pass an int var ‘by reference’ (by passing a pointer to the int).
I say ‘pseudo’ because, as we’ll see in the functions section, we are still technically passing by value–it just so happens that this value is a memory address that allows us to modify the original variable.
Now we can finally discuss arrays.
When we declare a variable as an array of a data type, we are kind of creating a pointer to the first element of that array (i.e. at index 0), and then storing all subsequent elements right next to each other in memory. (Arrays are more than just a pointer, but that’s outside the scope of this post).
For example, given an array of five int elements:
int intArr[5] = {1,21,34,15,9};
- the memory address of
intArr[1]would be at the location of the memory address ofintArr[0], plus one. - the memory address of
intArr[2]would be at the location of the memory address ofintArr[0], plus two, and so on.
That is to say:
&intArr[2] == &intArr[0] + 2;
would be true.
Here’s a helpful C program illustrating this further, with two arrays, one of ints, and then one of chars. Several things to note first:
- The comments to the right indicate what the output of the line would be.
- The
sizeof()function returns the byte size of the argument. - The
printf()function requires specifying the var format to be outputted. A few examples used here:%dindicates a digit,%pfor a pointer / memory address, and%cfor a char.\nadds a carriage return. - Note the different byte sizes of each different type
(on my compiler:int= 4,char= 1). - Note that the incremental memory address difference between each element in the array is that array type’s byte size (e.g. for the int array, each memory location is incremented by 4 bytes; for char, by 1 byte)
- Note that the array name is exactly the same thing as the memory address of the first element. Here,
1=>trueand0=>false.
#include <stdio.h>
int main() {
int intArr[5] = {16,27,38,49,50};
int intSize = sizeof(int); // [size in bytes]
int intArrSize = sizeof(intArr); // [size in bytes]
printf("size of int: %d\n", intSize); // size of int: 4
printf("size of intArr: %d\n", intArrSize); // size of intArr: 20
printf("%p => %d\n", intArr, *intArr); // 0x7ff7bc868070 => 16
printf("%p => %d\n", &intArr[0], intArr[0]); // 0x7ff7bc868070 => 16
printf("%p => %d\n", &intArr[1], intArr[1]); // 0x7ff7bc868074 => 27
printf("%p => %d\n", &intArr[0]+1, *(&intArr[0]+1));// 0x7ff7bc868074 => 27
printf("%d\n\n", intArr == &intArr[0]); // 1
char charArr[3] = {'c','a','t'};
int charSize = sizeof(char); // [size in bytes]
int charArrSize = sizeof(charArr); // [size in bytes]
printf("size of char: %d\n", charSize); // size of char: 1
printf("size of charArr: %d\n", charArrSize); // size of charArr: 3
printf("%p => %c\n", charArr, *charArr); // 0x7ff7b37fb033 => c
printf("%p => %c\n", &charArr[0], charArr[0]); // 0x7ff7b37fb033 => c
printf("%p => %c\n", &charArr[1], charArr[1]); // 0x7ff7b37fb034 => a
printf("%p => %c\n", &charArr[0]+1, *(&charArr[0]+1));// 0x7ff7b37fb034 => a
printf("%d\n\n", charArr == &charArr[0]); // 1
}
Another point is worth discussing from the above. You may have surmised that because we can calculate the byte size of the entire array, we can therefore determine how many elements are in the array by dividing the total array byte size against the byte size of each element.
However, we can only do this when we are in the same scope as where the array was defined. If we were to pass an array as an argument to a function, we must also pass the array’s length.
That’s why, when we receive args/flags passed by the user to our CLI application, we receive not only the array of strings (i.e. actually, an array of pointers to the first char of each string), but also an integer that represents the count of the args received, i.e. the number of array elements–like so:
#include <stdio.h>
int main(int argCount, char *args[]) {
if (argCount > 1) { // program call is itself the first arg (at index of 0)
for(int i=1; i < argCount; i++) {
printf("arg%d: %s\n", i, args[i]);
}
} else {
printf("you did not pass any args besides the program call\n");
}
return 0;
}
Note that in the above, C knows we want to print a string and not just one char because of the use of %s. Try adding this line within the for loop too. First try to guess what it’ll do, and then run it:
printf("arg%d: %c\n", i, *args[i]);
C uses a clever trick to mark the end of a set of chars that constitute a string: an additional '\0' char at the end! Read up on the strlen() function in the <string.h> library to see how you could print the last two chars of each arg string (including the end marker).
Now that we have a solid foundation of types, including pointers, arrays, and strings, it’s time to explore functions.
2. Functions
Functions in C always pass by value, and never by reference. That means that whatever arguments you pass to a function get copied into the scope of that function call that is pushed onto the call stack.
Similarily, any other variable that gets created inside that function only exists temporarily for as long as we’re in that function. Once the function gets popped off the stack, all variables in that scope are lost.
The only piece of data that a lower stack gets back from a function popped off the stack is in the return value. That’s why each function’s declaration includes its return type (e.g. main() returns an int).
Before I learned C, I thought that not having a garbage collector meant that we’d need to manually keep track of and manually get rid of all variables whenever we didn’t need them anymore. But that is not the case.
Any variable that is created using a standard type declaration inside a function or inside any block (e.g. inside if, while, for, etc) is automatically cleared as soon as you return from the function or exit the block scope. You do not need to manually release it.
How then do we modify variables inside a higher function and be able to access them later after we return from that function and, say, are back in main()?
There are two possible ways:
- define the variables in the lower callstack (e.g. inside
main()) and then pass pointers to them as arguments to the function higher on the callstack. After you return from the higher function, you can still access those variables since you’re still in that stack’s scope, which is where they were defined. - define the variables using the Heap instead of in a stack. And that’s where not having a garbage collector means having to manually free the memory of those variables.
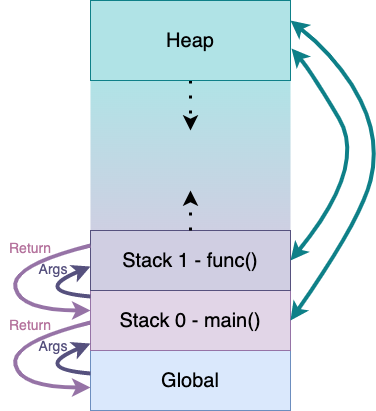
3. The Heap
As the image above indicates, you can access variables stored in the Heap from any function, anytime, for as long as your program lives. Of course, you’d still need the pointer to that memory location.
Functions that recursively call themselves keep pushing more and more functions on the stack, eating into the memory space available for the heap. Doing so too many times can eventually create the infamous ‘stack overflow’ situation, crashing the application.
Similarly, adding more and more data on the heap eats into the space available for function call stacks.
To store data on the heap instead of the stack, you use a specific function called malloc() defined in the <stdlib.h> library, which returns a pointer to the memory allocated, which you can then pass around. calloc() is another similar function you can use to allocate memory on the heap, which differs from malloc in that it additionally initializes the memory you allocated with its 0 equivalent–so it’s a little slower–but it also returns a pointer.
To repurpose an already allocated memory pointer and use it for something else, you can use realloc().
With any of the above, the memory used by this pointer never gets cleared until you manually clear it using the free() function. Here’s an example:
char *myHeapMemory = malloc(10 * sizeof(char)); // memory for up to 10 chars
if (myHeapMemory == NULL) { // always check for NULL
// exit gracefully, because you weren't able to allocate memory successfully
}
// do stuff with myHeapMemory
free(myHeapMemory); // when done, don't forget to free the memory!
Allocating memory on the heap is referred to as dynamic memory allocation, which seems like a misnomer, because it seems the exact opposite–from the programmer’s perspective at least, it’s a very manual process. But perhaps the word dynamic here is used from the perspective of the machine, meaning that the memory is allocated dynamically at runtime, as opposed to statically.
That concludes our brief exploration of C. It’s a fun language to learn, and is known for being the leanest and fastest way to do system-level work, including building an entire operating system.
There are no additional runtime environments needed, and everything compiles down to a single binary. You can meticulously define and control the memory you use, which ensures you only allocate what you actually need.
No wonder it’s still going strong today, several decades after it was first invented.
Vahid Dejwakh
Software Engineer at Microsoft;
Lover of good music and poetry
Vahid writes about interesting ideas at the intersection of software, system design, data, philosophy, psychology, policy, and business. He enjoys coffee and has a palate for spicy and diverse foods.